Blog
AI2推出至今以來最大的開放數據集,以用來訓練語言模型。

AI2推出至今以來最大的開放數據集,以用來訓練語言模型。
August 20, 2023
這個數據集被稱為Dolma,是研究小組計劃的開放語言模型(OLMo)的基礎(Dolma是“Data to feed OLMo's Appetite”的縮寫)。由於該模型旨在提供AI研究社群免費使用和修改,因此(AI2研究人員主張)創造它所使用的數據集也應該如此。
這是AI2首次提供與OLMo有關的“數據產物”,在部落格文章中,該組織的Luca Soldaini解釋了團隊用於使其適合AI消費的來源選擇,和各種過程的基本原理。(他們一開始就指出:“一篇更全面的論文正在進行中。”)
儘管像OpenAI和Meta這樣的公司公佈了他們用於構建語言模型的數據集的一些重要統計數據,但許多資訊被視為專有資訊。除了阻礙了大規模的審查和改進之外,人們還在猜測,也許這種封閉的方法是因為數據未能合法或合乎道德地獲得:例如,擷取的資訊來自於許多作者書籍的盜版拷貝。
你可以在由AI2建立的此圖表中看到,最大和最新的模型只提供了研究人員可能想了解有關特定數據集的一些資訊。移除了哪些資訊,為什麼?什麼被認為是高品質與低品質的文本?個人詳細資訊是否得到了適當的刪除?
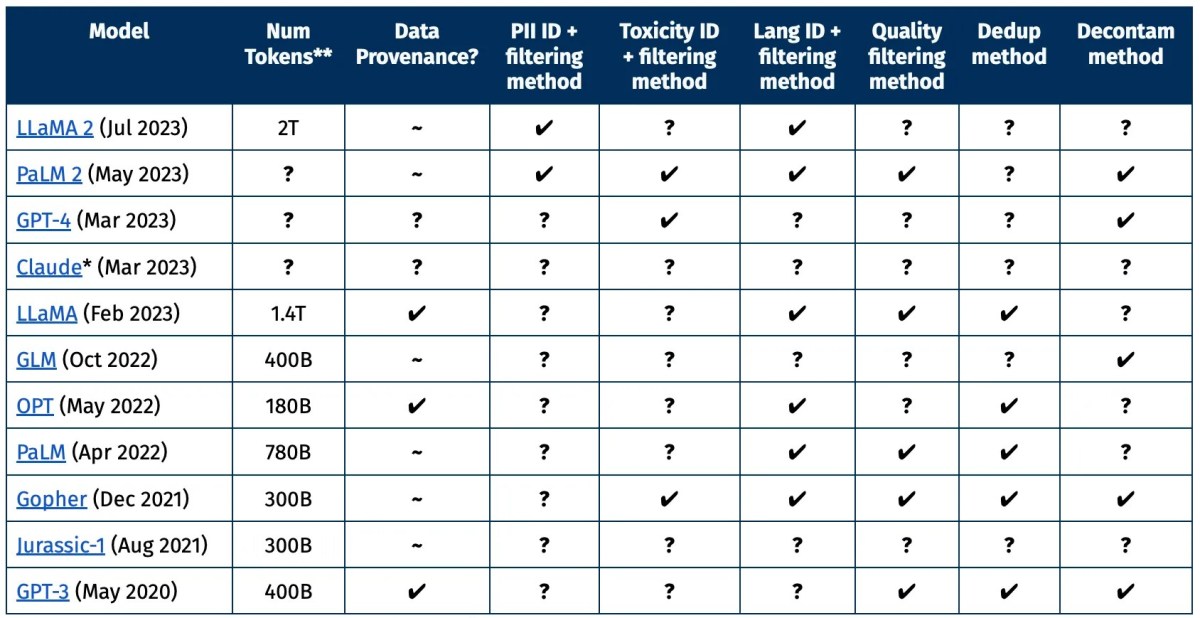
當然,這些公司在激烈競爭的AI格局下,有權保護其模型訓練過程的秘密。但對於公司以外的研究人員來說,這使得這些數據集和模型更加不透明,且難以研究或複製。
AI2的Dolma目的與上述案例相反,所有的來源和過程(例如,如何以及為什麼將其修剪為原始英語文本)都公開記錄。
這不是第一個嘗試開放數據集的專案,但它是迄今為止最大的(30億個token,一個AI本地的內容量度量)並且,他們聲稱,使用和許可權方面最簡單。它使用“中風險產物的
ImpACT許可證”,你可以在此處查看詳細資訊。但本質上,它要求Dolma的潛在用戶:
- 提供聯繫資訊和預期的使用案例
- 披露任何Dolma衍生創作
- 根據相同的許可證分發這些衍生物
- 同意不將Dolma應用於各種禁止的領域,例如監視或假資訊。
對於那些擔心儘管AI2的最大努力,他們的一些個人數據可能已經進入數據庫的人,這裡有一個移除請求表格。這是針對特定情況的,而不僅僅是一個普通的“不要使用我”的事情。
如果這一切聽起來讓你產生興趣,可以通過Hugging Face訪問Dolma。
新聞原址:AI2 drops biggest open dataset yet for training language models | TechCrunch