Blog
OpenAI超對齊團隊努力控制超級智慧AI

OpenAI超對齊團隊努力控制超級智慧AI
December 16, 2023
重點摘要:
新聞內文:
當投資者們準備在薩姆·奧特曼(Sam Altman)被毫不禮貌地從OpenAI開除後採取核武器級反應時,奧特曼正在策劃重返公司,OpenAI的超對齊(Superalignment)團隊成員正在努力研究如何控制比人類更聰明的AI。
至少,這是他們希望給人的印象。
本週,我與超對齊團隊的三名成員:科林·伯恩斯(Collin Burns)、帕維爾·伊茲邁洛夫(Pavel Izmailov)和利奧波德·阿申布倫納(Leopold Aschenbrenner)通了電話。他們當時在紐奧良參加NeurIPS年度機器學習會議,介紹OpenAI在確保AI系統按照預期行為方面的最新工作。
OpenAI於7月成立超對齊團隊,旨在開發引導、調節和管理「超級智慧」AI系統的方法:即智力遠遠超過人類的理論系統。
伯恩斯說:「目前,我們基本上可以對齊比我們笨的模型,或者最多達到人類水平的模型」。「對齊一個實際上比我們更聰明的模型要困難得多,我們甚至如何做到這一點?」
超對齊努力是由OpenAI聯合創辦人兼、科學家伊利亞·蘇茨克弗領導的,這在7月並未引起人們的關注。但鑑於蘇茨克弗是最初推動奧特曼被解僱的人之一,現在看來確實讓人意外。雖然一些報導暗示蘇茨克弗在奧特曼重返後處於「懸而未決」的狀態,但OpenAI的公關告訴我,蘇茨克弗的確仍在領導超對齊團隊。
超對齊在AI研究社區內是一個有點敏感的話題。一些人認為這個子領域尚未成熟;其他人則暗示它是一個轉移注意力的假話。
儘管奧特曼將OpenAI與曼哈頓計劃進行了比較,甚至組建了一個團隊來探索AI模型以防止「災難性風險」,包括化學和核威脅,但一些專家說,幾乎沒有證據表明該公司的技術將很快獲得結束世界、超越人類智慧的能力,甚至可能永遠不會。這些專家補充說,迫在眉睫的超級智能的主張只會故意轉移人們的注意力,並分散人們對當前迫切AI監控問題的關注,如算法偏見和AI的傾向性。
就其價值而言,蘇茨克弗似乎真誠地相信AI,可能有朝一日構成存在的威脅。他據說甚至在公司郊遊時燒毀了一個木製雕像,以展示他對防止AI危害人類的承諾,並為超對齊團隊的研究命令了OpenAI計算的相當大一部分,20%的現有計算機晶片。
阿申布倫納說:「最近AI的進步非常迅速,我可以向你保證它並沒有放慢」。「我認為我們很快就會達到人類水平的系統,但它不會止步於此。我們將直接進入超人類系統……那麼我們如何對齊超人類AI系統並使它們安全?這真的是全人類面臨的最重要的未解決技術問題」。
超對齊團隊目前正試圖構建可能適用於未來強大AI系統的治理和控制框架。考慮到「超級智慧」的定義是激烈爭論的主題,這不是一項簡單的任務。但團隊目前採取的方法是使用一個較弱、較不複雜的AI模型
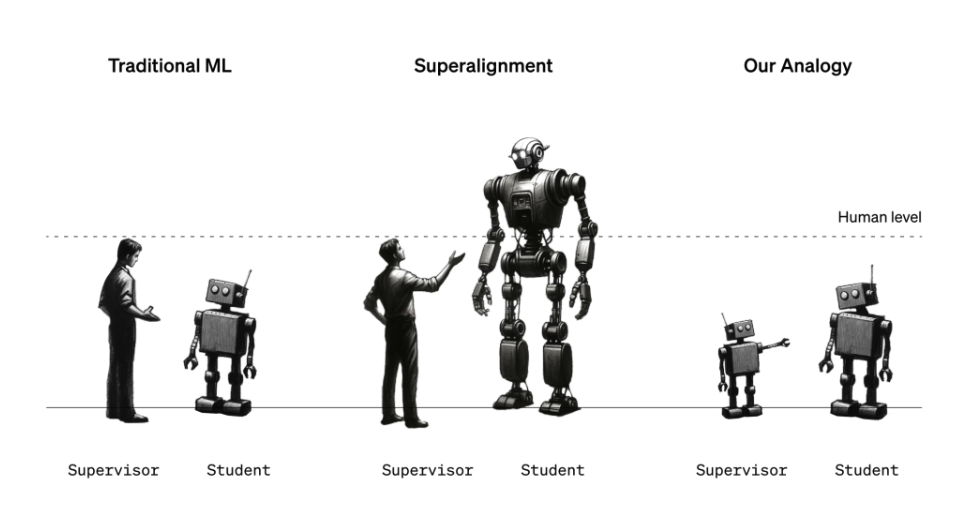
(例如GPT-2)來引導一個更先進、複雜的模型(GPT-4)朝向理想方向,並遠離不理想的方向。
伯恩斯說:「我們嘗試做的很多事情是告訴模型該做什麼,並確保它會這樣做」。「我們如何讓模型遵循指示,讓模型只幫助真實的事物,而不是編造事實?我們如何讓模型告訴我們它生成的代碼是安全的還是惡劣行為?這些是我們希望透過我們的研究實現的任務類型」。
但等一下,你可能會說:「AI指導AI與防止對人類構成威脅的AI有什麼關係?」好吧,這是一個比喻:弱模型應該是人類監督者的代表,而強模型代表超級智能AI。超對齊團隊說,類似於可能無法理解超級智慧AI系統的所有復雜性和細微差別的人類,弱模型無法「理解」強模型的所有復雜性和細節,使這種設置對於驗證超對齊假設非常有用。
伊茲邁洛夫解釋道:「你可以想象一個六年級的學生試圖監督一個大學生」。「假設這個六年級生試圖告訴這個大學生他大致知道如何解決的任務……即使這位六年級生的監控在細節上可能會出錯,但仍然有希望這位大學生會理解要點,並且能夠完成這項任務比監督者更好」。
在超對齊團隊的設置中,一個對特定任務進行微調的弱模型生成標籤,用於向強模型「傳達」該任務的大致內容。考慮到這些標籤,強模型可以根據弱模型的意圖更或少正確地進行推廣。
團隊聲稱,弱模型-強模型方法甚至可能在減少幻覺方面取得突破性進展。
阿申布倫納說:「幻覺實際上非常有趣,因為內部來看,模型實際上知道它所說的事情是事實還是虛構」。「但是今天這些模型的訓練方式,人類監督者會獎勵他們『贊』、『踩』。所以有時人們無意中會獎勵模型對事物的陳述,這些事物要么是虛假的,要么是模型實際上不了解的。如果我們的研究成功,我們應該開發出一些技術,我們可以基本上召喚模型的知識,我們可以將這種召喚應用於事實或虛構,並使用此來減少幻覺」。
但這個比喻並不完美。所以OpenAI希望眾包想法。
為此,OpenAI正在啟動一個1000萬美元的資助計劃,以支持超級智能對齊的技術研究,其中部分資金將保留給學術實驗室、非營利組織、個人研究人員和研究生。OpenAI還計劃於2025年初舉辦一次關於超對齊的學術會議,在會議上分享和推廣超對齊獎金入圍者的工作。
值得注意的是,資助計劃的一部分資金將來自前谷歌CEO和董事長埃里克·施密特。施密特(奧特曼的熱情支持者)正在迅速成為AI末日主義的代言人,他聲稱危險的AI系統的到來迫在眉睫,而監管機構對此準備不足。這不是出於一種利他主義感,必然地,《協議》和《連線》的報導指令人好奇的是,這項資助的部分資金將來自前谷歌CEO兼董事長埃里克·施密特(Eric Schmidt)。施密特是奧特曼(Sam Altman)的熱情支持者,正迅速成為AI災難主義的代表人物,他聲稱危險的AI系統即將到來,而監管機構對此準備不足。當然,這不一定是出於利他主義。《協議》(Protocol)和《連線》(Wired)的報導指出,作為一名積極的AI投資者,施密特在商業上將從美國政府實施他提出的加強AI研究的藍圖中獲益匪淺。
因此,施密特的捐款可能會被看作是透過懷疑的鏡頭進行的虛假標榜。施密特的個人財富估計約為240億美元,他已經投入數億美元於其他明顯較少關注倫理的AI企業和基金,包括他自己的。
當然,施密特否認這是這種情況。
他在一份電子郵件聲明中說:「AI和其他新興技術正在重塑我們的經濟和社會。確保它們與人類價值觀保持一致至關重要,我很自豪能夠支持OpenAI的新[資助],負責任地開發和控制AI,以造福公眾」。
實際上,這樣一個動機明顯的商業人物的參與,讓人不禁問:OpenAI的超對齊研究,以及它鼓勵社群提交給其未來會議的研究,是否會供任何人自由使用?
超對齊團隊向我保證,是的,OpenAI的研究及從OpenAI獲得超對齊相關工作的資助和獎項的其他人的工作,都將公開分享。我們將會追蹤公司履行這一承諾。
阿申布倫納(Aschenbrenner)說:「我們的使命不僅是為了我們模型的安全,也是為了其他實驗室模型和先進AI的安全。這真的是我們為全人類造福,安全建立[AI]的使命的核心。我們認為進行這項研究對於使其有益並確保其安全至關重要」。
新聞原址: https://techcrunch.com/2023/12/14/openai-thinks-superhuman-ai-is-coming-and-wants-to-build-tools-to-control-it/?ref=futurepedia
- OpenAI的超對齊團隊正研究如何控制智力超越人類的AI系統,這項工作由該公司創辦人伊利亞·蘇茨克弗領導,目的是開發引導和管理「超級智慧」AI系統的方法。
- 這個團隊正在探索如何對齊比人類更聰明的AI模型,目前的方法包括使用較弱、較不複雜的AI模型來引導更先進、複雜的模型,並減少幻覺問題。
- OpenAI已啟動一個1000萬美元的資助計劃來支持超級智慧對齊的技術研究,部分資金來自前Google CEO埃里克·施密特,這項研究將與社群共享並公開進行。
新聞內文:
當投資者們準備在薩姆·奧特曼(Sam Altman)被毫不禮貌地從OpenAI開除後採取核武器級反應時,奧特曼正在策劃重返公司,OpenAI的超對齊(Superalignment)團隊成員正在努力研究如何控制比人類更聰明的AI。
至少,這是他們希望給人的印象。
本週,我與超對齊團隊的三名成員:科林·伯恩斯(Collin Burns)、帕維爾·伊茲邁洛夫(Pavel Izmailov)和利奧波德·阿申布倫納(Leopold Aschenbrenner)通了電話。他們當時在紐奧良參加NeurIPS年度機器學習會議,介紹OpenAI在確保AI系統按照預期行為方面的最新工作。
OpenAI於7月成立超對齊團隊,旨在開發引導、調節和管理「超級智慧」AI系統的方法:即智力遠遠超過人類的理論系統。
伯恩斯說:「目前,我們基本上可以對齊比我們笨的模型,或者最多達到人類水平的模型」。「對齊一個實際上比我們更聰明的模型要困難得多,我們甚至如何做到這一點?」
超對齊努力是由OpenAI聯合創辦人兼、科學家伊利亞·蘇茨克弗領導的,這在7月並未引起人們的關注。但鑑於蘇茨克弗是最初推動奧特曼被解僱的人之一,現在看來確實讓人意外。雖然一些報導暗示蘇茨克弗在奧特曼重返後處於「懸而未決」的狀態,但OpenAI的公關告訴我,蘇茨克弗的確仍在領導超對齊團隊。
超對齊在AI研究社區內是一個有點敏感的話題。一些人認為這個子領域尚未成熟;其他人則暗示它是一個轉移注意力的假話。
儘管奧特曼將OpenAI與曼哈頓計劃進行了比較,甚至組建了一個團隊來探索AI模型以防止「災難性風險」,包括化學和核威脅,但一些專家說,幾乎沒有證據表明該公司的技術將很快獲得結束世界、超越人類智慧的能力,甚至可能永遠不會。這些專家補充說,迫在眉睫的超級智能的主張只會故意轉移人們的注意力,並分散人們對當前迫切AI監控問題的關注,如算法偏見和AI的傾向性。
就其價值而言,蘇茨克弗似乎真誠地相信AI,可能有朝一日構成存在的威脅。他據說甚至在公司郊遊時燒毀了一個木製雕像,以展示他對防止AI危害人類的承諾,並為超對齊團隊的研究命令了OpenAI計算的相當大一部分,20%的現有計算機晶片。
阿申布倫納說:「最近AI的進步非常迅速,我可以向你保證它並沒有放慢」。「我認為我們很快就會達到人類水平的系統,但它不會止步於此。我們將直接進入超人類系統……那麼我們如何對齊超人類AI系統並使它們安全?這真的是全人類面臨的最重要的未解決技術問題」。
超對齊團隊目前正試圖構建可能適用於未來強大AI系統的治理和控制框架。考慮到「超級智慧」的定義是激烈爭論的主題,這不是一項簡單的任務。但團隊目前採取的方法是使用一個較弱、較不複雜的AI模型
(例如GPT-2)來引導一個更先進、複雜的模型(GPT-4)朝向理想方向,並遠離不理想的方向。
伯恩斯說:「我們嘗試做的很多事情是告訴模型該做什麼,並確保它會這樣做」。「我們如何讓模型遵循指示,讓模型只幫助真實的事物,而不是編造事實?我們如何讓模型告訴我們它生成的代碼是安全的還是惡劣行為?這些是我們希望透過我們的研究實現的任務類型」。
但等一下,你可能會說:「AI指導AI與防止對人類構成威脅的AI有什麼關係?」好吧,這是一個比喻:弱模型應該是人類監督者的代表,而強模型代表超級智能AI。超對齊團隊說,類似於可能無法理解超級智慧AI系統的所有復雜性和細微差別的人類,弱模型無法「理解」強模型的所有復雜性和細節,使這種設置對於驗證超對齊假設非常有用。
伊茲邁洛夫解釋道:「你可以想象一個六年級的學生試圖監督一個大學生」。「假設這個六年級生試圖告訴這個大學生他大致知道如何解決的任務……即使這位六年級生的監控在細節上可能會出錯,但仍然有希望這位大學生會理解要點,並且能夠完成這項任務比監督者更好」。
在超對齊團隊的設置中,一個對特定任務進行微調的弱模型生成標籤,用於向強模型「傳達」該任務的大致內容。考慮到這些標籤,強模型可以根據弱模型的意圖更或少正確地進行推廣。
團隊聲稱,弱模型-強模型方法甚至可能在減少幻覺方面取得突破性進展。
阿申布倫納說:「幻覺實際上非常有趣,因為內部來看,模型實際上知道它所說的事情是事實還是虛構」。「但是今天這些模型的訓練方式,人類監督者會獎勵他們『贊』、『踩』。所以有時人們無意中會獎勵模型對事物的陳述,這些事物要么是虛假的,要么是模型實際上不了解的。如果我們的研究成功,我們應該開發出一些技術,我們可以基本上召喚模型的知識,我們可以將這種召喚應用於事實或虛構,並使用此來減少幻覺」。
但這個比喻並不完美。所以OpenAI希望眾包想法。
為此,OpenAI正在啟動一個1000萬美元的資助計劃,以支持超級智能對齊的技術研究,其中部分資金將保留給學術實驗室、非營利組織、個人研究人員和研究生。OpenAI還計劃於2025年初舉辦一次關於超對齊的學術會議,在會議上分享和推廣超對齊獎金入圍者的工作。
值得注意的是,資助計劃的一部分資金將來自前谷歌CEO和董事長埃里克·施密特。施密特(奧特曼的熱情支持者)正在迅速成為AI末日主義的代言人,他聲稱危險的AI系統的到來迫在眉睫,而監管機構對此準備不足。這不是出於一種利他主義感,必然地,《協議》和《連線》的報導指令人好奇的是,這項資助的部分資金將來自前谷歌CEO兼董事長埃里克·施密特(Eric Schmidt)。施密特是奧特曼(Sam Altman)的熱情支持者,正迅速成為AI災難主義的代表人物,他聲稱危險的AI系統即將到來,而監管機構對此準備不足。當然,這不一定是出於利他主義。《協議》(Protocol)和《連線》(Wired)的報導指出,作為一名積極的AI投資者,施密特在商業上將從美國政府實施他提出的加強AI研究的藍圖中獲益匪淺。
因此,施密特的捐款可能會被看作是透過懷疑的鏡頭進行的虛假標榜。施密特的個人財富估計約為240億美元,他已經投入數億美元於其他明顯較少關注倫理的AI企業和基金,包括他自己的。
當然,施密特否認這是這種情況。
他在一份電子郵件聲明中說:「AI和其他新興技術正在重塑我們的經濟和社會。確保它們與人類價值觀保持一致至關重要,我很自豪能夠支持OpenAI的新[資助],負責任地開發和控制AI,以造福公眾」。
實際上,這樣一個動機明顯的商業人物的參與,讓人不禁問:OpenAI的超對齊研究,以及它鼓勵社群提交給其未來會議的研究,是否會供任何人自由使用?
超對齊團隊向我保證,是的,OpenAI的研究及從OpenAI獲得超對齊相關工作的資助和獎項的其他人的工作,都將公開分享。我們將會追蹤公司履行這一承諾。
阿申布倫納(Aschenbrenner)說:「我們的使命不僅是為了我們模型的安全,也是為了其他實驗室模型和先進AI的安全。這真的是我們為全人類造福,安全建立[AI]的使命的核心。我們認為進行這項研究對於使其有益並確保其安全至關重要」。
新聞原址: https://techcrunch.com/2023/12/14/openai-thinks-superhuman-ai-is-coming-and-wants-to-build-tools-to-control-it/?ref=futurepedia