Blog
Meta推出Llama 3系列生成式人工智慧模型,性能達到行業領先水平

Meta推出Llama 3系列生成式人工智慧模型,性能達到行業領先水平
April 19, 2024
重點摘要:
- Meta發布了Llama 3系列生成式人工智慧模型,包括80億參數的Llama 3 8B和700億參數的Llama 3 70B,性能在24,000 GPU集群上訓練後達到行業領先水平。
- Llama 3系列在多項基準測試中超越了其他開源模型,包括MMLU、ARC、DROP等,並在至少九個基準測試中超越了Mistral的「Mistral 7B」和Google的「Gemma 7B」。
- Meta表示,Llama 3模型提供更多的「可操控性」,更低的拒絕回答問題的可能性,並在各種用例中表現出色,如編碼建議、雜學問題和STEM領域的高準確度。

新聞內文:
Meta推出了其Llama系列開源生成式人工智慧模型的最新版本:「Llama 3」。更準確地說,該公司推出了新的Llama 3系列中的兩個模型,其餘模型將在未來的某個未指定日期發布。Meta將這些新模型(包括包含80億參數的Llama 3 8B和包含700億參數的Llama 3 70B)描述為在性能方面與上一代Llama模型相比的「重大飛躍」。(參數基本上定義了人工智慧模型在問題上的技能,比如分析和生成文本;通常情況下,參數數量越多的模型比參數數量較少的模型更具備能力)。事實上,Meta表示,就各自的參數數量而言,Llama 3 8B和Llama 3 70B在兩個制定的24,000 GPU集群上訓練後,是當今性能最佳的生成式人工智慧模型之一。
這是一個相當大的宣稱。那麼,Meta是如何支持這一點的呢?該公司指出Llama 3模型在像MMLU(試圖測量知識)、ARC(試圖測量技能獲取)和DROP(測試模型對文本片段的推理能力)等流行人工智慧基準測試中的分數。正如我們之前所述,這些基準測試的用處和有效性存在爭議。但無論好壞,它們仍然是像Meta這樣的人工智慧參與者評估其模型的少數標準化方式之一。
在至少九個基準測試中,Llama 3 8B超越了其他開源模型,如Mistral的「Mistral 7B」和Google的「Gemma 7B」,這兩者都包含70億參數:MMLU、ARC、DROP、GPQA(涉及生物、物理和化學問題)、HumanEval(代碼生成測試)、GSM-8K(數學應用題)、MATH(另一個數學基準測試)、AGIEval(問題解決測試庫)和BIG-Bench Hard(常識推理評估)。
現在,Mistral 7B和Gemma 7B並不算是最尖端的(Mistral 7B於去年九月發布),在Meta引用的一些基準測試中,Llama 3 8B的得分僅比它們高出幾個百分點。但Meta還聲稱,參數數量更大的Llama 3模型,即Llama 3 70B,與旗艦生成式人工智慧模型相競爭,包括Google的「Gemini」系列中的最新版本Gemini 1.5 Pro。
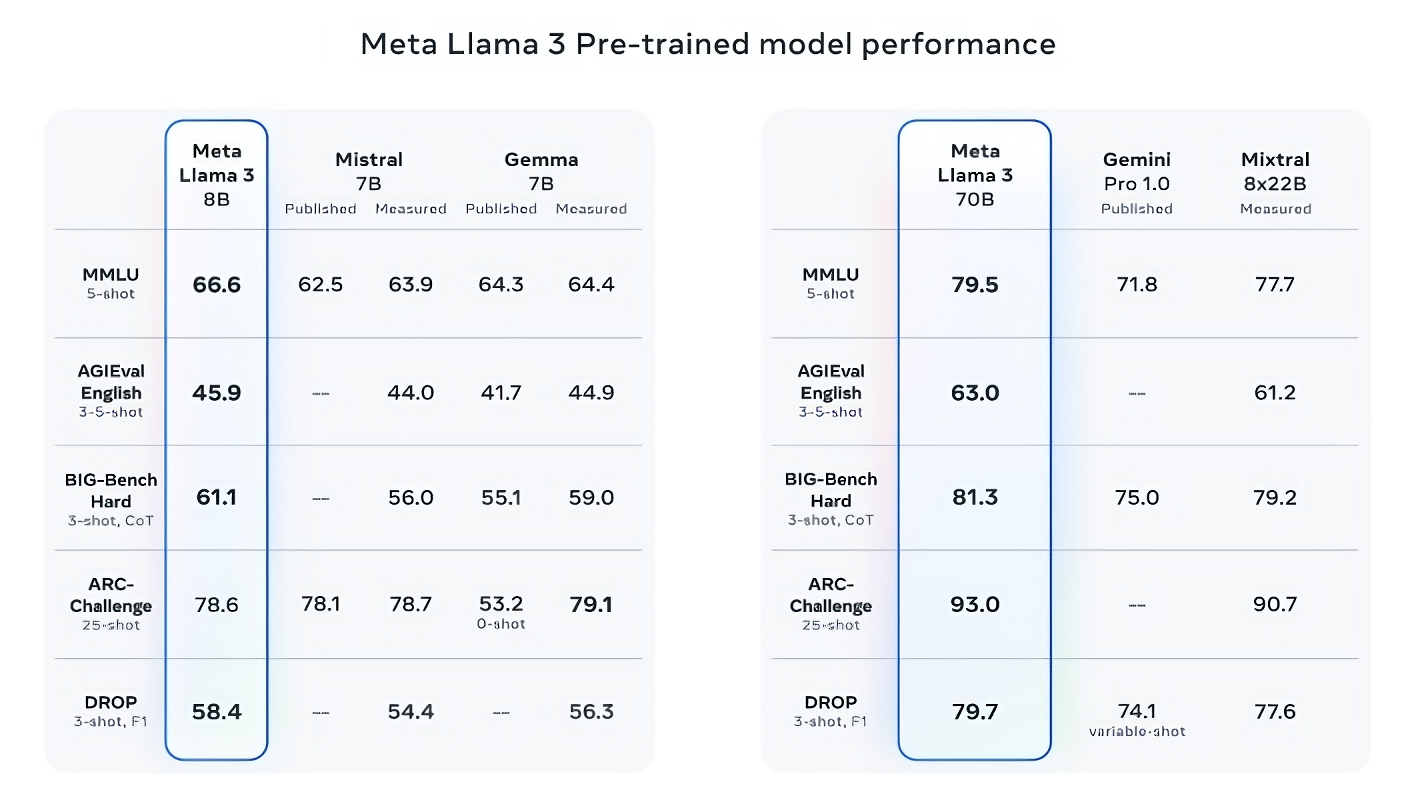
Llama 3 70B在MMLU、HumanEval和GSM-8K上超越了Gemini 1.5 Pro,雖然它無法與Anthropic最強大的模型「Claude 3 Opus」相媲美,但在五個基準測試(MMLU、GPQA、HumanEval、GSM-8K和MATH)上,Llama 3 70B的得分優於Claude 3系列中第二弱的模型Claude 3 Sonnet。
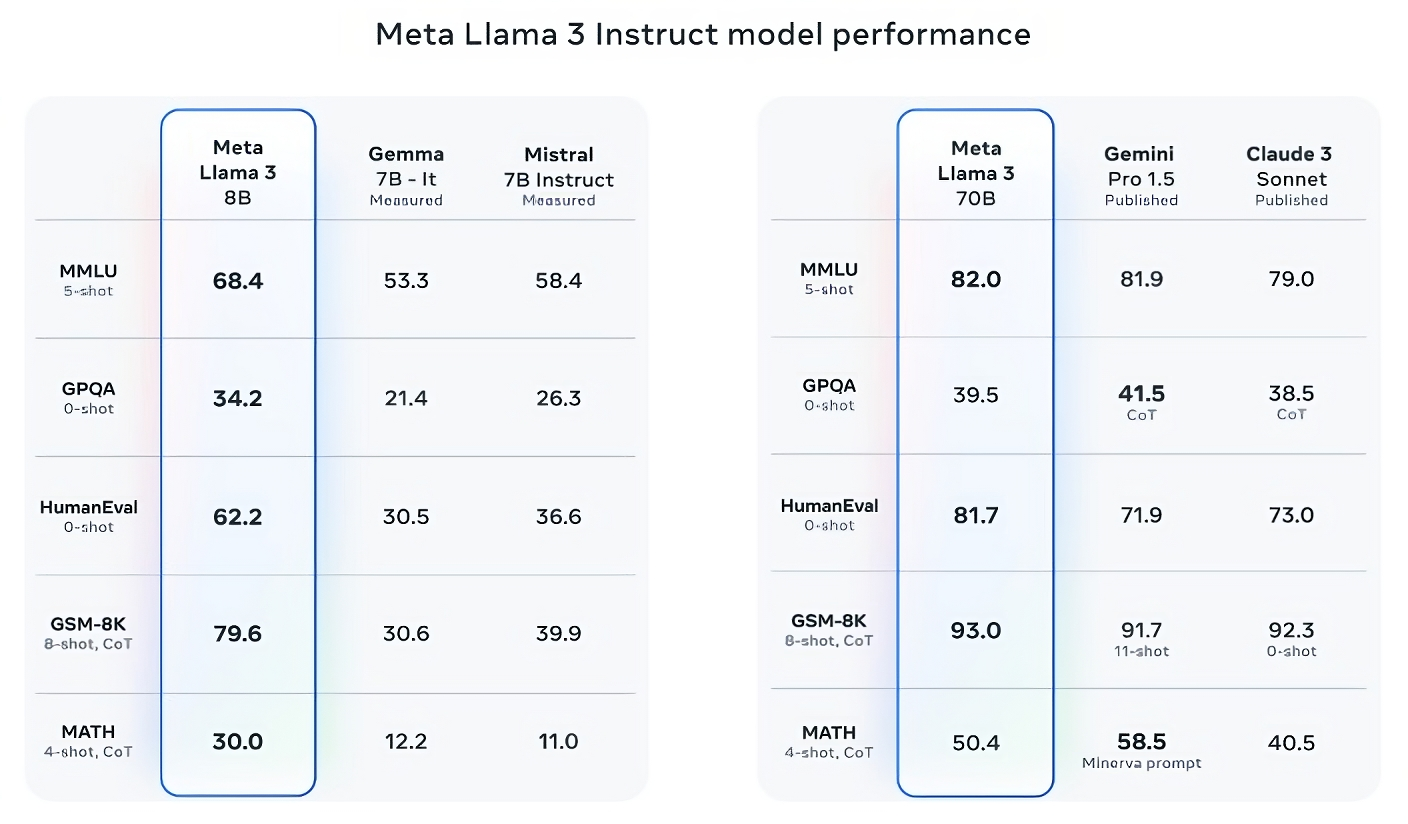
值得一提的是,Meta還開發了自己的測試庫,涵蓋了從編碼和創意寫作到推理和摘要等各種用例,而驚喜的是,Llama 3 70B在這些測試中擊敗了Mistral的「Mistral Medium」模型、OpenAI的GPT-3.5和Claude Sonnet。Meta表示,他們封閉了建模團隊對測試庫的訪問,以保持客觀性,但顯然,考慮到測試庫是由Meta自行設計的,測試結果必須帶有懷疑。
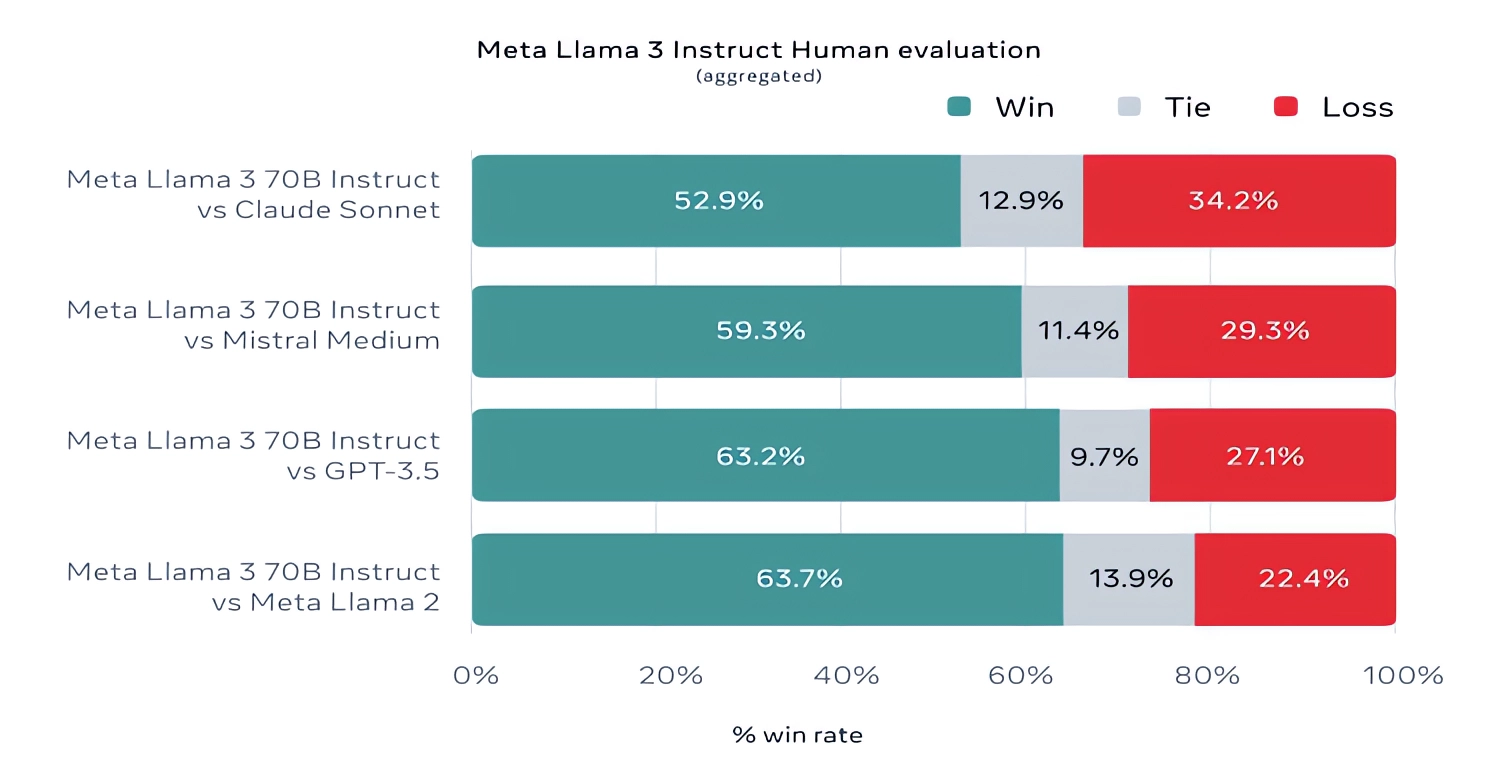
更具定性的是,Meta表示,使用新的Llama模型的使用者應該期待更多的「可操控性」,更低的拒絕回答問題的可能性,以及對於雜學問題、歷史相關問題以及STEM領域(如工程學和科學)和一般編碼建議的更高準確度。這部分歸功於更大的數據庫:一個包含15萬億個標記的集合,或者是一個令人難以置信的約7500億字的集合,是Llama 2訓練集大小的七倍。(在AI領域,「標記」指的是原始數據的細分部分,就像詞「fantastic」中的音節「fan」、「tas」和「tic」一樣。)
這些數據從哪里來呢?好問題。Meta不會透露,僅透露說它來自「公開可用的來源」,包含了比Llama 2訓練數據集多四倍的代碼,以及該集合的5%含有非英文數據(約30種語言),以提高在英語以外的語言上的性能。Meta還表示,它使用了合成數據(即AI生成的數據)來為Llama 3模型創建更長的文檔,以進行訓練,這種做法由於可能存在性能缺陷而引起了一些爭議。
Meta在與TechCrunch共享的一篇部落格文章中寫道:「儘管我們今天發布的模型只是針對英文輸出進行了微調,但增加的數據多樣性有助於模型更好地識別細微差別和模式,並在各種任務中表現出色」。
許多生成式AI供應商將訓練數據視為競爭優勢,因此將其和相關訊息保密。但訓練數據的細節也是知識產權相關訴訟的潛在來源,這也是不願透露太多的另一個激勵因素。最近的報導顯示,為了與AI競爭對手保持步伐,Meta曾經使用受版權保護的電子書進行AI訓練,儘管該公司的律師曾警告,Meta和OpenAI是侵犯版權數據進行訓練的被告,其中包括喜劇演員莎拉·西爾弗曼。
那麼,關於毒性和偏見,這兩個與生成式AI模型(包括Llama 2)的常見問題,Llama 3是否有所改進呢?Meta回答:「是的」。
Meta表示,他們開發了新的數據過濾管道,以提高其模型訓練數據的品質,並更新了其兩個生成式AI安全套組,Llama Guard和CybersecEval,以防止Llama 3模型和其他模型的誤用和不需要的文本生成。該公司還推出了一個新工具,Code Shield,旨在檢測生成式AI模型中可能引入安全漏洞的代碼。
然而,過濾並不是絕對可靠的。而像Llama Guard、CyberSecEval和Code Shield這樣的工具也只能做到這樣多。(參見:Llama 2傾向於為問題編造答案,並洩露私人健康和財務訊息)。
我們將不得不等待看看Llama 3模型在野外的表現,包括在其他基準上進行學術測試。
Meta表示,Llama 3模型現已提供下載,並為Meta在Facebook、Instagram、WhatsApp、Messenger和網路上的Meta AI助手提供支持,未來將在AWS、Databricks、Google Cloud、Hugging Face、Kaggle、IBM的WatsonX、Microsoft Azure、Nvidia的NIM和Snowflake等一系列雲端平臺上提供托管形式。未來,將為AMD、AWS、Dell、Intel、Nvidia和高通等公司的硬體優化的版本也將提供。
Llama 3模型可能會廣泛使用。但您會注意到,我們使用「開放」來描述它們,而不是「開源」。這是因為,儘管Meta聲稱其Llama系列模型是面向研究和商業應用的,但它們並不像Meta想讓人們相信的那樣沒有任何附加條件。是的,它們可用於研究和商業應用。但是,Meta禁止開發人員使用Llama模型來訓練其他生成模型,而擁有超過7億月活躍使用者的應用開發者必須向Meta請求特殊許可證,而Meta將根據其自身的酌情決定是否授予該許可證。
更強大的Llama模型即將來臨。
Meta表示,它目前正在訓練超過4000億參數的Llama 3模型。這些模型能夠「以多種語言進行對話」,接受更多數據並理解圖像等其他形式的數據,這將使Llama 3系列與Hugging Face的Idefics2等開放版本保持一致。
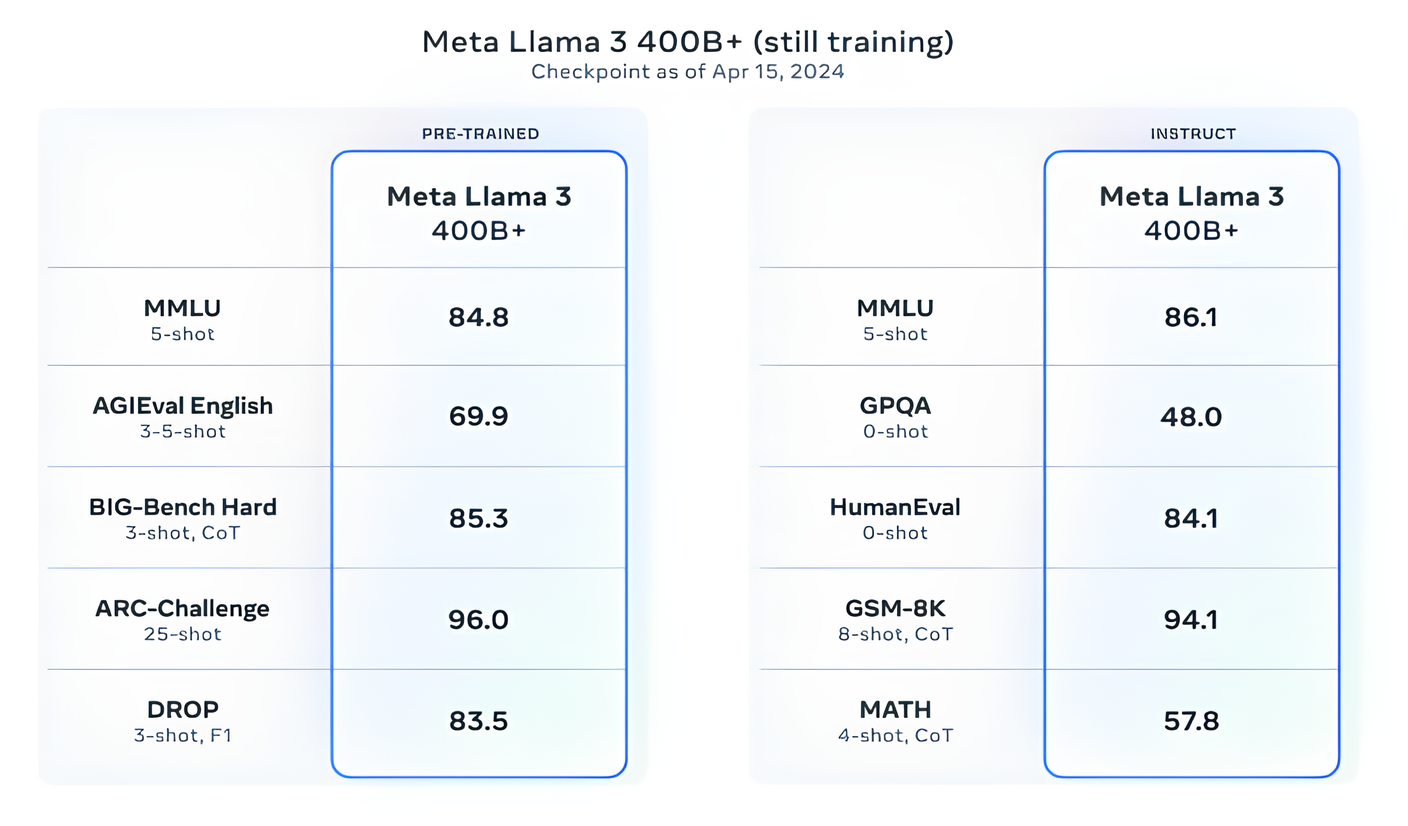
Meta在一篇部落格文章中寫道:「我們在不久的將來的目標是使Llama 3具有多語言和多模態功能,具有更長的上下文並繼續改進在核心大型語言模型功能上的整體性能,如推理和編碼」。「還有很多值得期待的」。
新聞原址: https://techcrunch.com/2024/04/18/meta-releases-llama-3-claims-its-among-the-best-open-models-available/