Blog
OpenAI強化內部安全,新小組監督AI風險管理以對抗潛在威脅
OpenAI強化內部安全,新小組監督AI風險管理以對抗潛在威脅
December 19, 2023
重點摘要:
新聞內文:
OpenAI正在擴大其內部安全流程,以抵禦有害AI的威脅。一個新的「安全顧問小組」將置於技術團隊之上,向領導層提出建議,董事會被授予否決權。當然,他們是否真的會使用這個權力是另一個問題。
通常這些政策的內容並不需要報導,因為實際上這些都是一些閉門會議,其功能和責任流程對外界來說很少有人能知曉。儘管在這種情況下也可能是如此,但最近的領導層動盪和不斷發展的AI風險討論,值得我們關注世界領先的AI 開發公司是如何處理安全問題的。
在一份新文件和部落格文章中,OpenAI討論了他們更新的「準備框架」,可以想像在11月的震盪後進行了一些重大調整,當時移除了董事會中兩位最「減速主義者」成員:依然在公司中擔任有所改變角色的Ilya Sutskever(已完全離開)和Helen Toner。
更新的主要目的似乎是顯示出識別、分析和決定如何應對他們正在開發的模型固有的「災難性」風險的明確途徑。正如他們所定義的:
「災難性風險是指可能導致數千億美元的經濟損害或導致許多人嚴重受傷或死亡的任何風險;這包括但不限於存在性風險」。
(存在性風險是指「機器崛起」類型的事情。)
在生產中的模型由一個「安全系統」團隊管理;這是針對ChatGPT等系統的系統性濫用,可以通過 API 限制或調整來緩解。正在開發的前沿模型則由「準備」團隊負責,該團隊試圖在模型發布前識別和量化風險。然後是「超對齊」團隊,該團隊正在研究「超智慧」模型的理論導則,我們可能還未達到或已經接近。
前兩個類別是真實而非虛構的,具有相對容易理解的準則。他們的團隊會根據四個風險類別評估每個模型:網路安全、「說服」(例如偽造訊息)、模型自主性(即自行行動)和CBRN(化學、生物、輻射和核威脅;例如創造新型病原體的能力)。
這些風險評估假定了各種緩解措施:例如,合理的不願描述製造汽油彈或煙花炸彈的過程。在考慮了已知緩解措施後,如果模型仍被評估為「高」風險,則不能部署,如果模型具有任何「關鍵」風險,則不會進一步開發。
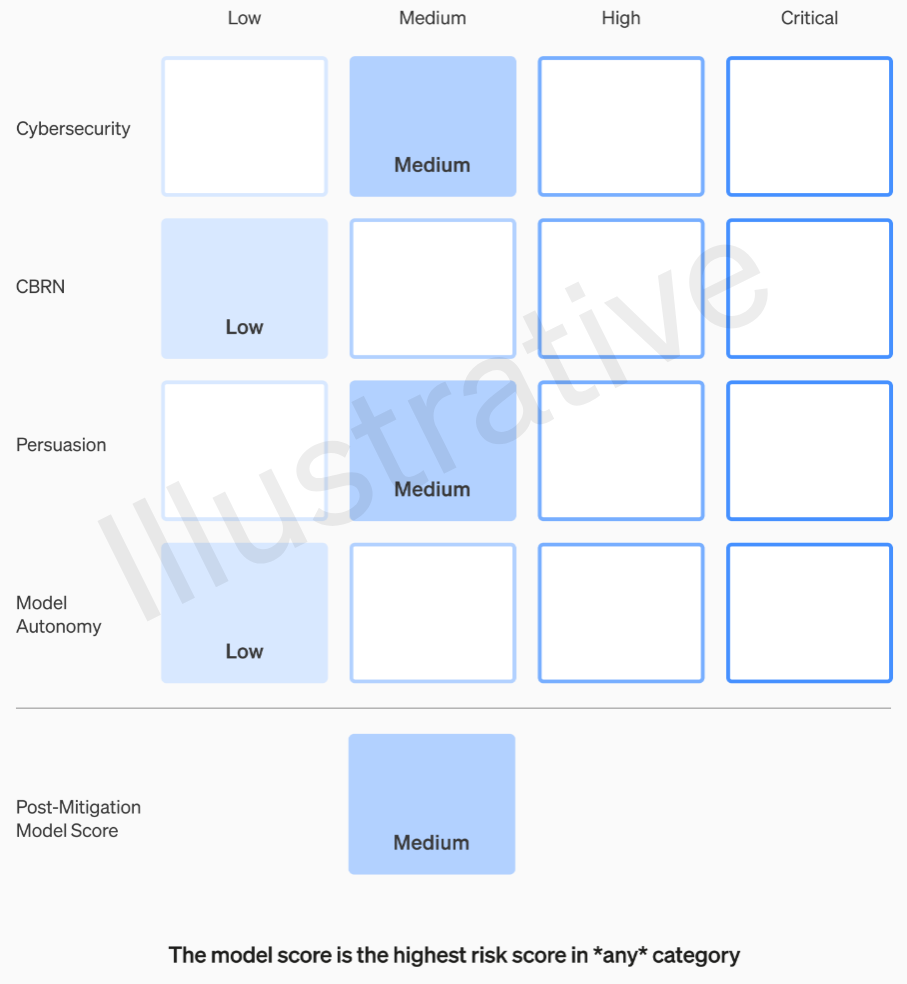
這些風險等級實際上記錄在框架中,以防您想知道它們是否會留給某些工程師或產品經理的自由裁量。
例如,在網路安全部分,這是最實用的部分之一,透過一定因素「提高操作員在關鍵網路操作任務上的生產力」是「中等」風險。另一方面,高風險模型將「識別和開發針對硬化目標的高價值漏洞的概念證明,無需人為干預」。關鍵是「模型可以設計並執行針對硬化目標的全新網路攻擊策略,只需一個高層次的目標」。很顯然地,我們不希望這種情況發生(儘管它可能會賣出一大筆錢)。
我們已要求OpenAI提供有關如何定義和完善這些類別的更多資訊。例如,如果出現像「說服」或新類別下的真實虛假視頻的新風險。如果我收到回覆將更新本文。
因此,只有中等和高風險可一定程度上容忍。但製作這些模型的人不一定是評估它們並提出建議的最佳人選。出於這個原因,OpenAI正在建立一個「跨職能安全顧問小組」,該小組將位於技術層面之上,審查專家們的報告,並提出包括更高視角的建議。希望這將揭示一些「未知的未知數」,儘管它們本質上很難捕捉。
這個過程要求這些建議同時發送給董事會和領導層,我們理解為意味著CEO Sam Altman和CTO Mira Murati,以及領導層將決定是否發布或冷凍,但董事會將能夠推翻這些決定。
這將有望阻止類似於先前傳聞發生的事情,即在未獲得董事會意識或批准的情況下,高風險產品或流程獲得批准。當然,該劇的結果是邊緣化了兩個更關鍵的聲音,並任命了一些金錢導向的人(Bret Taylor和Larry Summers),他們很敏銳,但並不是AI專家。
如果專家小組提出建議,並且 CEO 根據這些訊息做出決策,這個友好的董事會真的會感到授權反駁他們並踩剎車嗎?如果他們這樣做,我們會聽到嗎?透明度相關問題除了承諾OpenAI將徵求獨立第三方審計之外幾乎沒有被提及。
假設開發了一個值得「關鍵」風險類別的模型。OpenAI在過去並不羞於宣揚這類事情,談論他們的模型有多強大,以至於他們拒絕發布它們,這是很好的廣告。但我們是否有任何這種保證會發生,如果風險是如此真實,而OpenAI對此如此關注?也許這是一個壞主意。但無論如何,這些都沒有提及。
新聞原址: https://techcrunch.com/2023/12/18/openai-buffs-safety-team-and-gives-board-veto-power-on-risky-ai/
- OpenAI正在擴展其內部安全流程,包括成立一個新的「安全顧問小組」,負責向技術團隊和領導層提出建議,董事會擁有否決權。
- OpenAI的更新「準備框架」旨在識別和評估開發中的模型固有的「災難性」風險,並定義四個主要風險類別:網路安全、說服、模型自主性和CBRN威脅。
- 透過這一框架,OpenAI旨在對模型進行綜合性風險評估和管理,其中包括跨職能的安全顧問小組的參與,以及對於具有關鍵風險的模型的嚴格限制。
新聞內文:
OpenAI正在擴大其內部安全流程,以抵禦有害AI的威脅。一個新的「安全顧問小組」將置於技術團隊之上,向領導層提出建議,董事會被授予否決權。當然,他們是否真的會使用這個權力是另一個問題。
通常這些政策的內容並不需要報導,因為實際上這些都是一些閉門會議,其功能和責任流程對外界來說很少有人能知曉。儘管在這種情況下也可能是如此,但最近的領導層動盪和不斷發展的AI風險討論,值得我們關注世界領先的AI 開發公司是如何處理安全問題的。
在一份新文件和部落格文章中,OpenAI討論了他們更新的「準備框架」,可以想像在11月的震盪後進行了一些重大調整,當時移除了董事會中兩位最「減速主義者」成員:依然在公司中擔任有所改變角色的Ilya Sutskever(已完全離開)和Helen Toner。
更新的主要目的似乎是顯示出識別、分析和決定如何應對他們正在開發的模型固有的「災難性」風險的明確途徑。正如他們所定義的:
「災難性風險是指可能導致數千億美元的經濟損害或導致許多人嚴重受傷或死亡的任何風險;這包括但不限於存在性風險」。
(存在性風險是指「機器崛起」類型的事情。)
在生產中的模型由一個「安全系統」團隊管理;這是針對ChatGPT等系統的系統性濫用,可以通過 API 限制或調整來緩解。正在開發的前沿模型則由「準備」團隊負責,該團隊試圖在模型發布前識別和量化風險。然後是「超對齊」團隊,該團隊正在研究「超智慧」模型的理論導則,我們可能還未達到或已經接近。
前兩個類別是真實而非虛構的,具有相對容易理解的準則。他們的團隊會根據四個風險類別評估每個模型:網路安全、「說服」(例如偽造訊息)、模型自主性(即自行行動)和CBRN(化學、生物、輻射和核威脅;例如創造新型病原體的能力)。
這些風險評估假定了各種緩解措施:例如,合理的不願描述製造汽油彈或煙花炸彈的過程。在考慮了已知緩解措施後,如果模型仍被評估為「高」風險,則不能部署,如果模型具有任何「關鍵」風險,則不會進一步開發。
這些風險等級實際上記錄在框架中,以防您想知道它們是否會留給某些工程師或產品經理的自由裁量。
例如,在網路安全部分,這是最實用的部分之一,透過一定因素「提高操作員在關鍵網路操作任務上的生產力」是「中等」風險。另一方面,高風險模型將「識別和開發針對硬化目標的高價值漏洞的概念證明,無需人為干預」。關鍵是「模型可以設計並執行針對硬化目標的全新網路攻擊策略,只需一個高層次的目標」。很顯然地,我們不希望這種情況發生(儘管它可能會賣出一大筆錢)。
我們已要求OpenAI提供有關如何定義和完善這些類別的更多資訊。例如,如果出現像「說服」或新類別下的真實虛假視頻的新風險。如果我收到回覆將更新本文。
因此,只有中等和高風險可一定程度上容忍。但製作這些模型的人不一定是評估它們並提出建議的最佳人選。出於這個原因,OpenAI正在建立一個「跨職能安全顧問小組」,該小組將位於技術層面之上,審查專家們的報告,並提出包括更高視角的建議。希望這將揭示一些「未知的未知數」,儘管它們本質上很難捕捉。
這個過程要求這些建議同時發送給董事會和領導層,我們理解為意味著CEO Sam Altman和CTO Mira Murati,以及領導層將決定是否發布或冷凍,但董事會將能夠推翻這些決定。
這將有望阻止類似於先前傳聞發生的事情,即在未獲得董事會意識或批准的情況下,高風險產品或流程獲得批准。當然,該劇的結果是邊緣化了兩個更關鍵的聲音,並任命了一些金錢導向的人(Bret Taylor和Larry Summers),他們很敏銳,但並不是AI專家。
如果專家小組提出建議,並且 CEO 根據這些訊息做出決策,這個友好的董事會真的會感到授權反駁他們並踩剎車嗎?如果他們這樣做,我們會聽到嗎?透明度相關問題除了承諾OpenAI將徵求獨立第三方審計之外幾乎沒有被提及。
假設開發了一個值得「關鍵」風險類別的模型。OpenAI在過去並不羞於宣揚這類事情,談論他們的模型有多強大,以至於他們拒絕發布它們,這是很好的廣告。但我們是否有任何這種保證會發生,如果風險是如此真實,而OpenAI對此如此關注?也許這是一個壞主意。但無論如何,這些都沒有提及。
新聞原址: https://techcrunch.com/2023/12/18/openai-buffs-safety-team-and-gives-board-veto-power-on-risky-ai/