Blog
上週AI新聞回顧:AI新創公司Midjourney挑戰版權風險,勇敢使用受保護作品

上週AI新聞回顧:AI新創公司Midjourney挑戰版權風險,勇敢使用受保護作品
March 18, 2024
重點摘要:
- AI新創公司Midjourney修改了服務條款,針對與公司的IP爭議政策相關的條款進行微調,顯示了對可能的法律爭端的信心。
- 一些供應商積極與內容創作者簽署許可協議,但Midjourney卻大膽使用受版權保護的作品進行訓練,可能面臨版權訴訟的風險。
- Midjourney的行為表明,若最終法庭裁決有利於公平使用原則,則其繼續使用受保護作品進行訓練的可能性很大。

新聞內文:
在一個如AI般快速發展的行業中跟進是一項艱鉅的任務。因此,在有一款AI可以代替你之前,這裡有一個方便的摘要,概述了機器學習世界的最新故事,以及我們沒有單獨報導的顯著研究和實驗。上週,AI新創公司「Midjourney」,這家正在開發圖像(以及即將推出的影音)生成器的公司,對其與公司的IP爭議政策相關的服務條款進行了一個小的、一不注意就會錯過的修改。這主要是將詼諧的語言替換為更像律師、無疑是以案例法為基礎的條款。但這個改變也可以被解讀為Midjourney堅信像自己這樣的AI供應商將在法庭上與其作品構成供應商訓練數據的創作者取得勝利的跡象。

Midjourney等的生成式AI模型是透過大量的示例進行訓練的,例如圖像和文本,通常來自於網路上的公共網站和數據庫。供應商聲稱,公平使用這一法律原則允許使用具有創造性的著作來製作次級創作,只要它是變革性的,就可以在模型訓練方面對其進行保護。但並非所有創作者都同意這一觀點,特別是考慮到越來越多的研究顯示,模型可以「重新呈現」訓練數據。
一些供應商已經採取了積極的方式,與內容創作者簽署許可協議,並為訓練數據集建立了「選擇退出」計劃。其他人則承諾,如果客戶因使用供應商的生成式AI工具而卷入侵犯版權的訴訟,他們將不需要為法律費用負責。
Midjourney不是那些積極主動的公司之一。
相反地,Midjourney在使用受版權保護的作品方面相當大膽,一度列出了成千上萬位藝術家的名單(其中包括主要品牌如Hasbro和Nintendo的插畫師和設計師)他們的作品被用於訓練Midjourney的模型。一項研究顯示,Midjourney在其訓練數據中還使用了電視節目和電影系列,從《玩具總動員》到《星際大戰》,再到《沙丘》及《復仇者聯盟》。
現在,有一種情況是,最終法庭裁決會對Midjourney有利。如果司法系統確定公平使用適用,那麼沒有什麼能阻止這家新創公司繼續以舊的和新的受版權保護的數據進行抓取和訓練。
但這似乎是一個冒險的賭注。
目前,Midjourney飛得很高,據報導已經實現了約2億美元的收入,而沒有一分錢的外部投資。但是律師是昂貴的。如果決定公平使用不適用於Midjourney的情況,它將在一夜之間被摧毀。
沒有風險,就沒有收益,對吧?
以下是過去幾天中一些其他值得注意的人工智慧事件:
AI輔助廣告引起了錯誤的關注:Instagram上的創作者抨擊了一位導演,該導演的商業廣告未給予另一位創作者(更難更令人印象深刻)的作品充分的認可。
在選舉前夕,歐盟當局正在警告AI平台:他們要求科技巨頭公司解釋他們防止選舉鬧劇的方法。
Google Deepmind希望你的合作遊戲夥伴是他們的AI:對3D遊戲遊玩進行訓練使代理人能夠執行自然語言中表述的簡單任務。
評估Rufus:上個月,Amazon宣布將在Android和iOS的Amazon購物應用中推出一個新的AI聊天機器人「Rufus」。我們提前獲得了試用,並且對Rufus所能做的事情(以及做得好的事情)感到失望。
更多機器學習
分子,它們是如何運作的?人工智慧模型在我們理解和預測分子動力學、構象等納米世界的各個方面上都很有幫助,否則可能需要昂貴、複雜的方法來進行測試。當然,你仍然需要進行驗證,但是像AlphaFold這樣的東西正在迅速改變這個領域。
微軟推出了一個名為ViSNet的新模型,旨在預測所謂的結構活性關係,即分子與生物活性之間的復雜關係。這還是非常實驗性的,絕對僅適用於研究人員,但是看到最前沿的技術手段正在解決硬科學問題總是令人鼓舞的。

曼徹斯特大學的研究人員專注於識別和預測COVID-19變異體,與ViSNet等純結構不同,更多地通過對冠狀病毒進化相關的大型基因數據集進行分析。
主要研究人員Thomas House表示:「在大流行期間產生的前所未有的大量基因數據要求我們改進我們的方法來進行彻底分析」。他的同事Roberto Cahuantzi補充道:「我們的分析作為概念驗證,展示了機器學習方法作為發現新興主要變異體的早期發現警報工具的潛力」。
人工智慧也可以設計分子,許多研究人員已經簽署了一項倡議,呼籲在這一領域加強安全性和道德性。儘管世界上最優秀的計算生物物理學家之一David Baker指出:「蛋白質設計的潛在益處遠超過了目前的危險」。作為AI蛋白質設計師的設計者,他確實會這樣說。但同樣地,我們必須警惕那些錯失要點、阻礙合法研究而讓惡意行為者自由發展的法規。
華盛頓大學的大氣科學家基於對土庫曼斯坦25年衛星圖像的人工智慧分析,提出了一個有趣的觀點。基本上,人們普遍認為,蘇聯解體後的經濟動盪導致排放減少的理解可能不是真實的,且事實上可能相反。
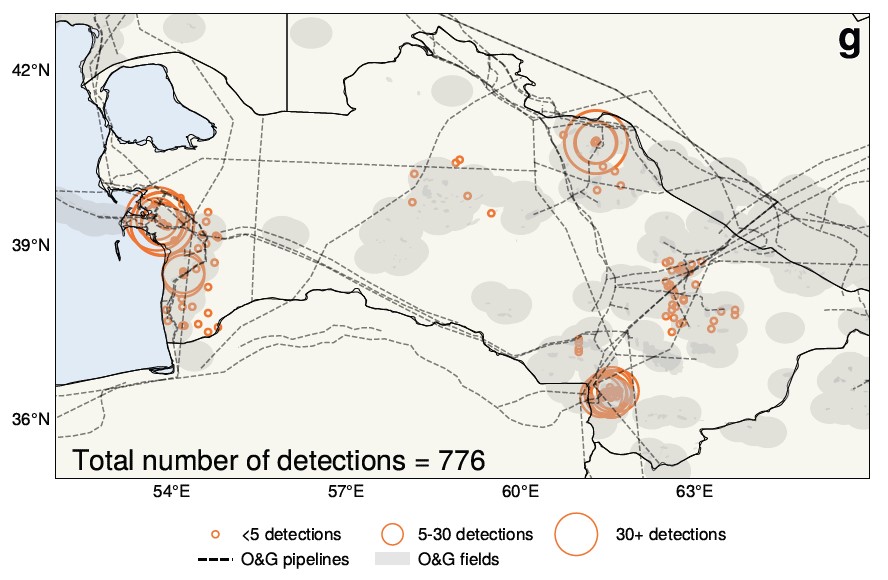
華盛頓大學教授Alex Turner表示:「我們發現,蘇聯解體似乎出乎意料地導致甲烷排放增加」。大量數據集和缺乏時間篩選使得這個話題成為人工智慧的一個自然目標,這導致了這種出乎意料的逆轉。
大型語言模型主要是在英文源數據上訓練的,但這可能影響的不僅僅是它們使用其他語言的能力。瑞士聯邦理工學院的研究人員研究了LlaMa-2的「潛在語言」,發現該模型在法語和中文之間進行翻譯時,似乎內部仍然會轉換為英文。然而,研究人員建議,這不僅僅是一個懶惰的翻譯過程,實際上該模型已經將其整個概念潛在空間結構化為英文概念和表示。但這重要嗎?很可能是。我們應該無論如何都應該使其數據集多樣化。
新聞原址: https://techcrunch.com/2024/03/16/this-week-in-ai-midjourney-bets-it-can-beat-the-copyright-police/